Building GPT from scratch
A walkthrough of (almost) everything that goes into a language model.

In this post, we create a baby GPT from scratch, make it sit through 66 hours' worth of Seinfeld and see what it picks up.
We'll progress through four increasingly complex AI models, culminating in a mini replica of the same model used by OpenAI. Along the way, we'll learn what goes on inside a large language model (LLM) and how the relatively simple architecture gives rise to such complex results.
Note: this is not a comprehensive guide for building your own GPT-4 (not least because the architecture is secret); we'll be focusing on the core concepts, leaving out details like layernorm, tokenization, and embeddings.
Structure
- What are language models trying to do?
- Level 1: n-gram
- Level 2: Neural network
- Level 3: Attention
- Level 4: English first, Seinfeld second
What are language models trying to do?
For most language models, the core challenge is text prediction: given the start of a sentence ('What do you '), we want to predict the next letter ('w'). For if we can predict the next letter, we can predict the next word. And if we can predict the next word, we can predict the next sentence. And if we can do that, it's a short hop to generating the code to video games and many other GPT-4 specialties.
This challenge is simple to state, but hard to achieve. A perfect text predictor would be a mathematics prodigy (what follows '599 x 2182='), a trivia buff ('Plato was born in '), and master of every other field on the internet.
To get a sense of how easy / hard this is, have a go below with sentences from the Seinfeld TV show:
Hard, right? I got 11%.
Modern large language models (LLMs) approach this challenge by devouring much of the internet, learning the web of patterns between different letters and words, and using these to form predictions. As we don't have the luxury of hundreds of GPU chips, we'll be training on the first 90% of Seinfeld, reserving the final 10% for blind testing. Let's jump in.
Level 1: n-gram
Given a sentence snippet e.g. 'all over the c', how do you predict the next letter based on the training text (the first 90% of Seinfeld)?
Here's a natural first approach: first, search the training text for every occurrence of that snippet; then, predict the letter that most commonly comes next.
If the sentence doesn't occur in the training text, we trim the end off until it does.

This and variants are frequently referred to as n-gram strategies (an n-gram is any sequence of n letters, for example, 'abc' is a 3-gram, and 'Kramer' is a 6-gram). In effect, we are using the frequencies of different n-grams in the training text to predict the next letter.
How does n-gram do?
It does pretty well accuracy-wise, getting the next letter right 62% of the time (you can compare this to your score on the game above).

If we let it keep predicting the next letter again and again, you get sentences like the below:

These have all been taken verbatim from various Seinfeld episodes, even the last (clearly 'NFT' doesn't occur in Seinfeld, so it picked a snippet starting 'is').
What's wrong with this?
Our model works by taking an input, scanning the script for the most similar chunk and parroting what follows. It's like a diligent student who has memorised the material, but falls apart on unfamiliar questions – there's no grasp of meaning. Humans don't learn this way. With our limited brain space, we couldn't afford it; so we compress information. For example, rather than rote learning times tables up to 1000, we learn basic arithmetic, enabling us to predict the same outcome (e.g. 21 x 23 = 483) with a fraction of the brain space. Likewise, we recognize synonyms (e.g., mother vs. mum) and understand that they can be used interchangeably in similar contexts. This way, knowledge about 'mother' can be easily applied to 'mum' and vice versa, again reducing the space needed.
Here's an example of the n-gram model screwing up:


Despite theoretically being presented with enough information to answer this (e.g. the line "FRANK: Your mother changed her mind... GEORGE: (gleeful, to Estelle) You did?!"), our n-gram model fails to understand, and therefore, predict. But GPT-4 gets it right.
We have two further problems:
- Certainty – our model is deterministic, meaning it assigns 100% probability to its prediction and 0% to anything else. Given it's wrong the majority of the time, this makes it perform poorly. And if it makes a guess which turns out to be wrong, it now has no idea what the right answer may be. This makes our model fragile – if something changes, e.g. a word goes out of fashion, or a character dies, then the performance significantly falls.
- Efficiency – it took over 15 minutes to generate 100 predictions, as we had to look through all 4m letters in the Seinfeld script. This is barely feasible for Seinfeld and rapidly becomes unfeasible for bigger texts.
So we want to change our model in three ways:
- Make it understand – give it limited brain capacity so rote memorisation is penalized vs. learning more space-efficient general concepts
- Make it probabilistic – instead of returning the most common letter, we'll return a set of probabilities (p(A), p(B), ..., p(z)) that each letter is next
- Make it more efficient – no combing through all the data just to make a single prediction
This leads us in a particular direction: neural networks.
Level 2: Neural network
Imagine a neural network as a box fitted with dials. It takes inputs e.g. "George " and spits out outputs e.g. "Costanza". Crucially, we can tweak the dials to produce different outputs e.g. "Bush".
To train a neural network you need three things:
- A neural network (NN) – a function that takes inputs to outputs
- A loss function – measures how well the model output compares to the target
- An optimiser – tweaks the dials to improve performance
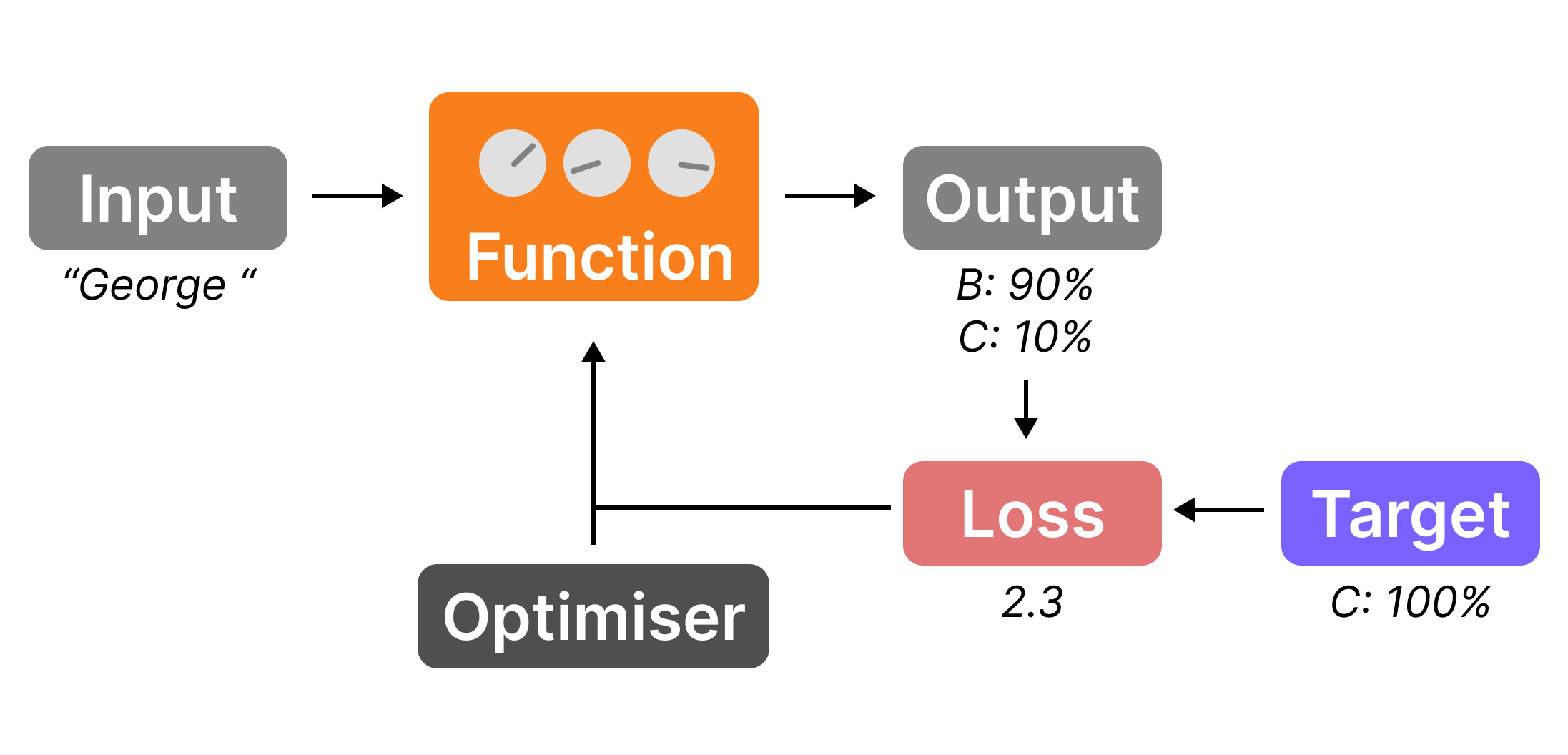
But what is a loss function?
A loss function is something that gives a high value if the output is far off the target (e.g. the next letter was 'a', which was predicted to be very unlikely), and a low value if the output is close to the target.
With our n-gram model, it was easy: loss is 0 if you get it right and 1 otherwise. With a probabilistic model, we need something different.
There are lots of different loss functions. For example, if the target next letterwas B and you thought the probability of this happening was p(B), you could say the loss is 1-p(B). Then if p(B)=1, your loss is 0, and if p(B)=0, your loss is 1.
For reasons I won't go into, we'll use 'cross-entropy loss', which is -log(p(B)). Now if p(B)=1, the loss is 0, and if p(B)=0, the loss is infinite (an outcome we really want to avoid).
But what is an optimiser?
An optimiser tells you how to tweak the dials to improve the loss. The most common type uses stochastic gradient descent and it's pretty much an algorithmic version of what a human would do if you were given control of the dials: 1) tweak the dials a bit and look how the loss changes 2) figure out which direction decreases the loss 3) move the dials in that direction 4) repeat.
You also need to decide how big a step to go in the downhill direction (called the learning rate) – too big and you might step over the valley and up the other side; too small and it will take forever. In general, models prefer larger learning rates earlier in training, which lessen over time.
To understand NNs in more detail (including what's inside the black box), I'd recommend 3Blue1Brown's video series.
How to use neural networks to predict the next letter
When first created, the baby NN won't be a good model (i.e. loss will be high), as the dials will be random. We need to train it with a four-step process:
- Input an example text – e.g. take a random chunk ("George C"), feed the first bit in ("George ") and hold back the last letter ("C") as the target we're looking to predict
- Model predicts output probabilities for next letter– e.g. "B"->90%, "C"->10%
- Compute the loss vs. the target – compare the probabilities with the target last letter ("C"->100%, the rest ->0%) and compute the loss. In this case, it would be high (-log(0.1)=2.3) as the model thought "C" was only 10% likely
- Update the dials – use the optimizer to ensure that next time with this input, "C" is given a higher probability and so the loss is lower
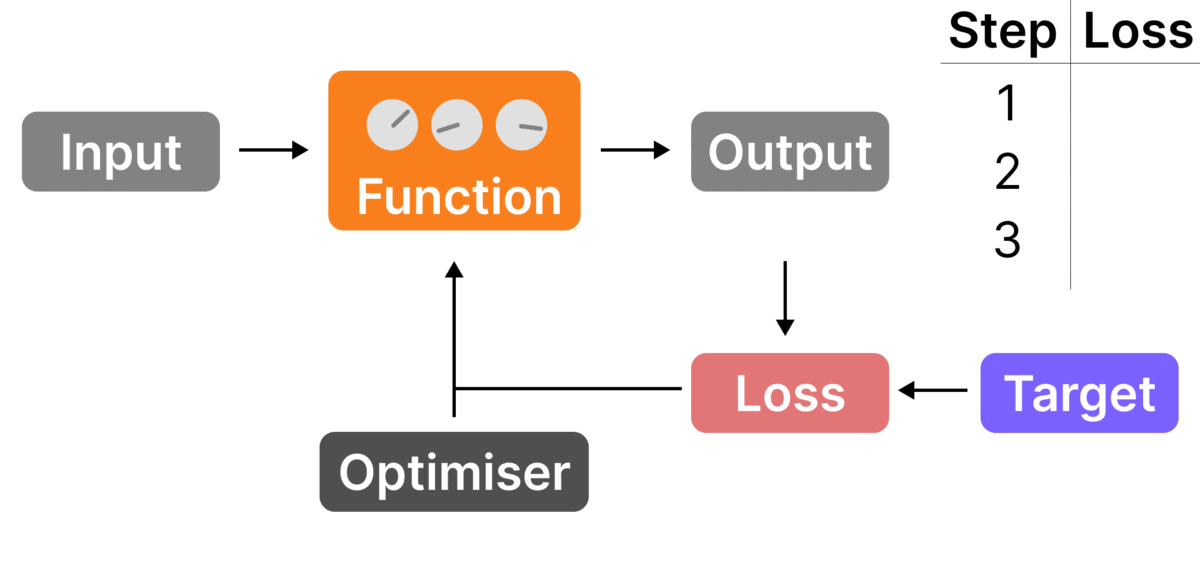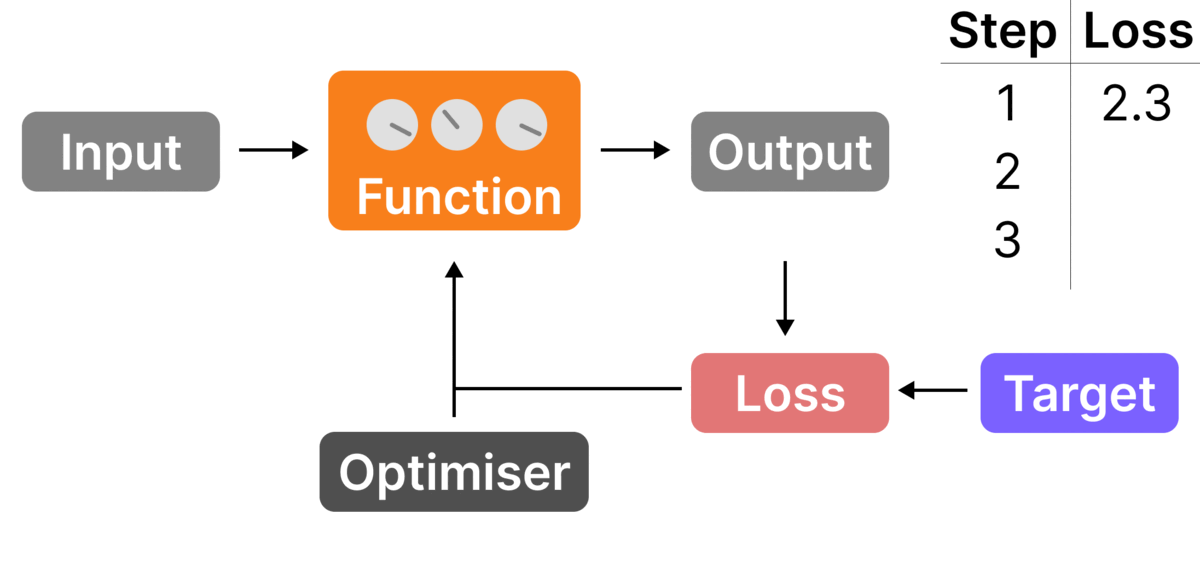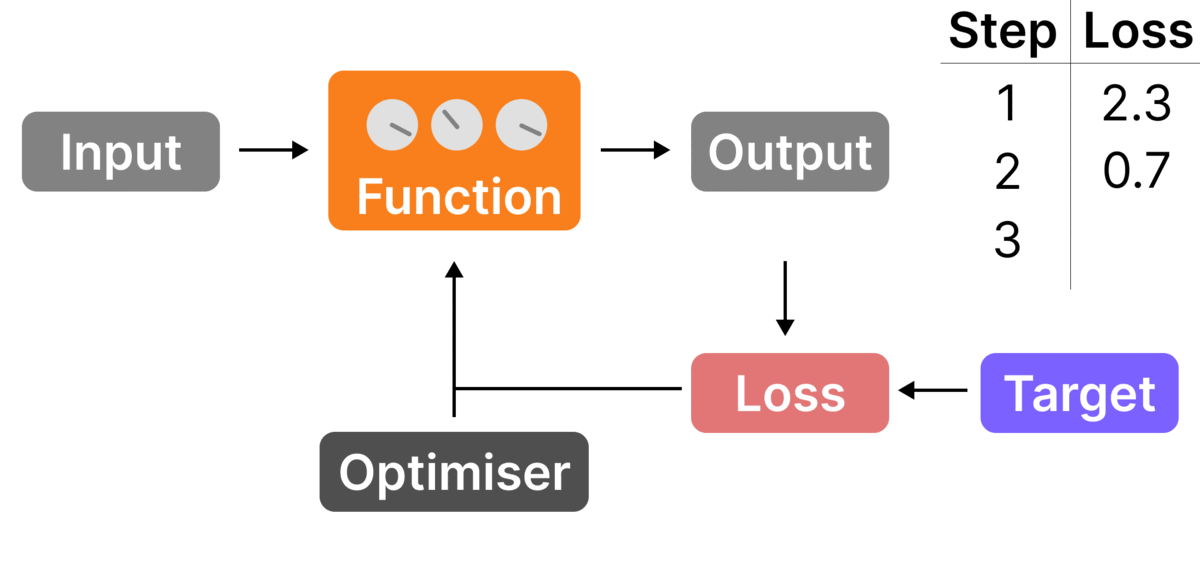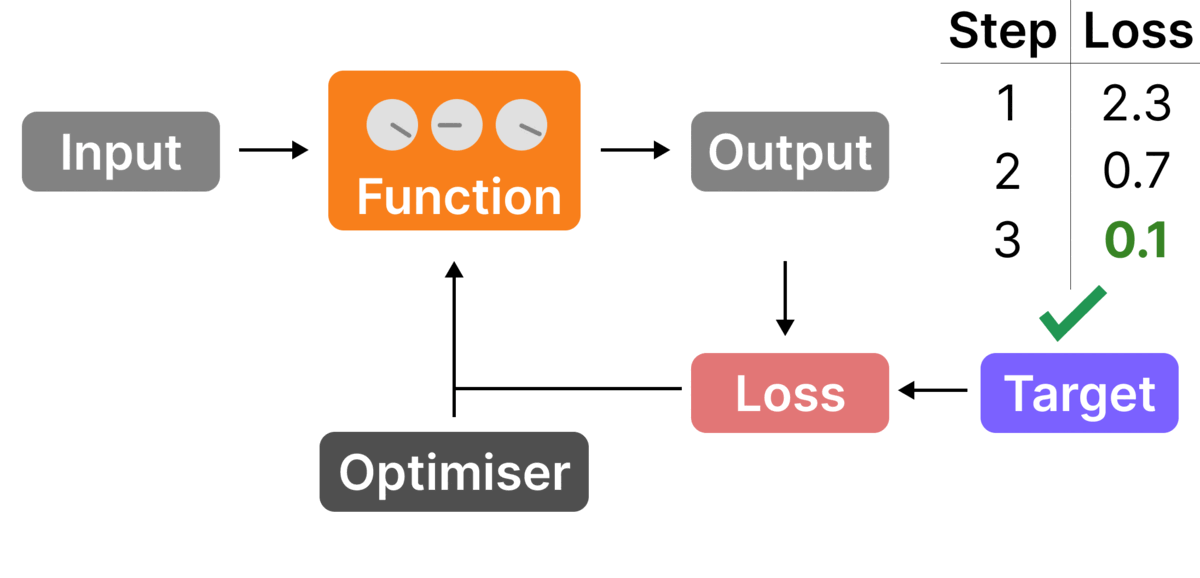
When we do this over thousands of examples, the neural network gets tuned to give the right outputs.
How does it perform?
Returning to the original challenge, we want to predict the next letter given the previous sentence. We're now judging accuracy on this task using a loss function, where the higher the loss, the less accurate our model is.
Below is a plot of how different neural networks perform, depending on how many letters from the previous sentence are inputted ('window size'):
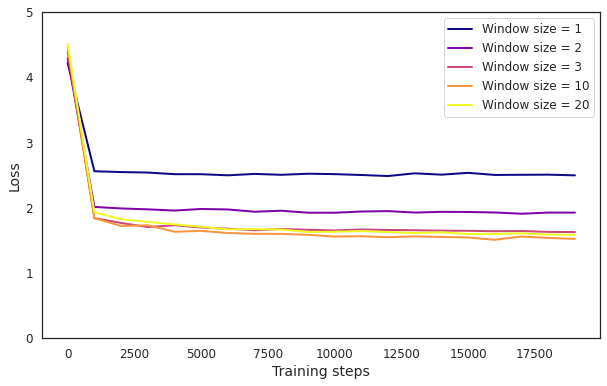
In general, it's not bad – similar to the n-gram model, the more hindsight we give it, the better it performs. The larger window sizes end up stuck at about 1.6 loss.
Here's some example text generated from window size = 20:

Pretty interesting. It's learnt some things e.g. script structure, character names, and some English. Moreover, the generation is crucially all new (compared to before). However, it's certainly not good: it mostly produces gibberish, George speaks after George, etc.
Also worrying is that increasing the length of input text (window size) from 10 to 20 seems to decrease accuracy. This suggests that the neural network is almost exclusively focusing on the last few letters to make predictions.
So why does increasing the amount of context not improve the performance?
The main reason is there's a key step in text prediction – deciding which information from earlier in the sequence is important – that simple neural networks (NNs) just aren't good at.
Before 2017, this was pretty much as good as it got. There were ways to get around some of the problems (e.g. using LSTMs) and get slightly lower losses, but these had problems of their own and couldn't scale up to much larger sequences. Conveniently, this isn't the end of the story.
Level 3: Attention
In 2017, researchers at Google published 'Attention is All You Need', which introduced a mechanism called 'attention' and an architecture called a 'transformer'.
The main idea
Instead of feeding all the letters into a neural network (NN) as-is, we feed each letter in individually, together with relevant information from the previous letters.
In practice, for each letter/character, there are two steps:
- Attention – get relevant information from the previous letters. What counts as relevant ultimately depends on the letter/character we're currently looking at. For example, the right bracket ')' might be looking for what happened before the bracket was opened, whereas 't' is looking for the last few letters to guess what word it is
- Simple neural network (NN) – feed the relevant information plus the current letter into a simple NN to predict the next letter
We let the NN focus on what it's good at and delegate the rest to a new attention mechanism. The combination of attention plus simple NN is called a transformer.
Sounds good in theory. But how does attention work in practice?
Everyone has a different story for what made attention finally 'click' for them. For me, I imagine it as dating.
If you're on a dating app, you have:
- What you're looking for – e.g. 'a good cook'
- People's profiles – e.g. 'I am a good cook'
- What they're actually like – e.g. 'good at cooking toast'
You're screening people's profiles based on what you're looking for to predict what they're actually like, which determines how well you'll work together.
Initially, you're not great at finding compatible people and swipe on the wrong profiles. But over multiple relationships, you update your preferences and therefore your swiping habits: a tricky long-distance relationship? Same town. A bad experience with Labradoodle? No pets. At the same time, people are trying to decide how to tweak their profiles and personalities to get matched with people they're compatible with.
The great thing about the dating market – and markets in general – is that this dance eventually converges on an equilibrium in which everyone gets matched optimally (don't quote me on this). In other words, every person finds the most relevant person for them (see where this is going?).
So you can picture attention as a dating market for letters:
- The current letter decides what it's looking for – called a query
- Each previous letter has a profile – called a key – and a message they'll communicate if matched – called a value
At first, the query, key and value functions will be random. But over time, letters will match and the relationship will go well (the value passed into the NN results in a good prediction) or poorly. And over time, letters will update their preferences and messages accordingly.
But unlike the human dating market, polygamy is actively encouraged. So eventually, every letter will have a room of previous letters most relevant to them. After weighting the letters by relevance, they'll jump in and head straight into the NN for prediction.
In a transformer, this combination of query, key and value functions is called an attention head. In practice, people create multiple different attention heads (multiple different dating markets) and feed outputs from each of them into the NN for next letter prediction – this lets attention heads specialise in certain things e.g. finding recent vowels.
And that's attention – the core feature of a transformer – in a nutshell.
OpenAI's GPT is comprised of a few transformers stacked end-to-end, the output from one forming the input to another (plus a few extra things mentioned in Footnotes).
To test it out, I trained a model with virtually identical architecture to GPT, but 50,000 times smaller. As a result, it takes 30 minutes to train on a single GPU chip vs. 355 years for a GPT-3 sized model.
Why can't a NN learn attention itself?
It certainly could – in fact a sufficiently powerful neural network can learn any smooth function. But we want it to learn quickly and efficiently with limited time, data and compute. And, as it turns out, learning which parts of an input to pay attention to is particularly slow and inefficient for the standard neural network architecture. Giving it an attention architecture is a helpful shortcut to speed it along the path.
How does it perform?
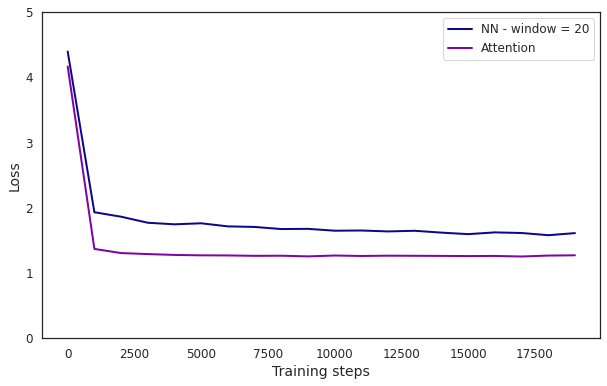
Quite a remarkable improvement. Here is an example generation:

That was a strange insight into the model's mind. But compared with the previous model, it has perfected the script structure, the proportion of English words is up from ~50% to ~90% and the grammar is significantly better. However, the sentences still don't make sense. But don't worry – we have one final trick up our sleeve.
The problem is the model has tried to use 66 hours of Seinfeld to learn the entire English language. While some non-native English speakers learn decent (albeit American) English from TV, they do it from a range of shows. And they already have an understanding of language from their mother tongue.
This suggests an approach for even better performance: first, teach our model English, then teach it Seinfeld.
Level 4: English first, Seinfeld second
The final innovation to improve Seinfeld generation involves first training a large Transformer model on lots of non-Seinfeld English text and subsequently retraining (fine-tuning) it on our specific task (i.e. Seinfeld scripts). This way it develops an understanding of English first and subsequently can better interpret Seinfeld when it watches it (just like us).
I trained a larger model (21M parameters) first on a collection of movie and TV show scripts (~380M characters) for 20,000 steps and subsequently trained it on Seinfeld. Here's how it performed:
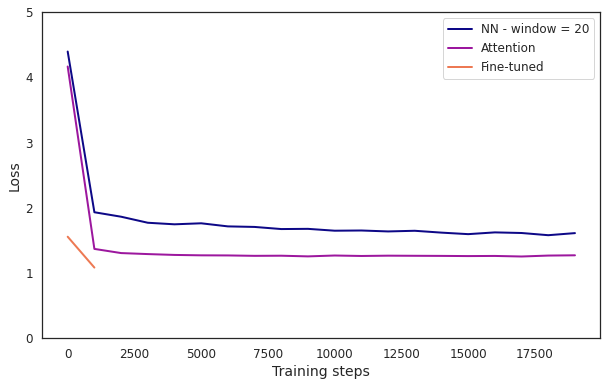
Another significant increase in performance. Interestingly, after only training on other movie / TV scripts (at step = 0), the new model's loss is lower than NN at step = 20k. In other words, a model that has never seen Seinfeld is better at predicting Seinfeld than a model that has only seen it (although still worse than our first attention model).
Try it yourself here (takes ~10 seconds):
The quality of the output is better yet again: almost all English words and grammar, clear scene structure, consistent characters. That said, it's still a bit nonsensical.
Despite this, the model scores 62% accuracy on the original letter prediction game across examples.
We could still do better: we could train a larger model on more data and a bigger window size, or try some of the model enhancements referenced in Meta's LLaMA model.
But for now, this is as far as we'll go. We've built a GPT model from scratch that achieves 62% prediction accuracy on Seinfeld. In doing so, you've hopefully understood more of what goes on inside a transformer, taken away some peculiar dating advice, and witnessed firsthand the outcome of an AI nurtured by Jerry, George, Elaine, and Kramer.
Footnotes
- I've skipped a few important transformer ingredients for simplicity e.g. layer normalisation, tokenization, embeddings, skip connections, positional encoding, learning rate scheduling – to learn many of these and build GPT for yourself, I'd recommend watching Andrej Karpathy's great video
- In this piece, 'attention' is used as shorthand for 'self-attention'. There are other types of attention e.g. 'cross-attention', but they are not relevant for GPT.
- Code available here
- Data: Seinfeld scripts, pre-training scripts